Explore Graph Databases: Comprehensive Guide to Technologies, Use Cases, and Performance
Graph databases represent a revolutionary approach to data management, leveraging graph structures to model relationships between data points. Unlike traditional databases that rely on tables, graph databases utilize nodes, edges, and properties to create a more intuitive representation of data. This article delves into the intricacies of graph database technology, exploring their unique features, use cases, and performance metrics. As businesses increasingly seek to harness complex data relationships, understanding graph databases becomes essential for tech enthusiasts, business professionals, and anyone interested in the evolving landscape of data management. We will cover the fundamental concepts of graph databases, their comparison with relational databases, the various query languages, and their applications across different industries.
What Are Graph Databases and How Do They Work?
Graph databases are designed to store and manage data in a way that emphasizes the relationships between data points. They operate on the principle of graph theory, where data is represented as nodes (entities) connected by edges (relationships). This structure allows for efficient querying and retrieval of complex data relationships, making graph databases particularly suitable for applications that require deep data analysis and connectivity. The primary benefit of graph databases lies in their ability to handle highly interconnected data, enabling faster queries and more insightful analytics compared to traditional relational databases.
Understanding Graph Database Technology and Models
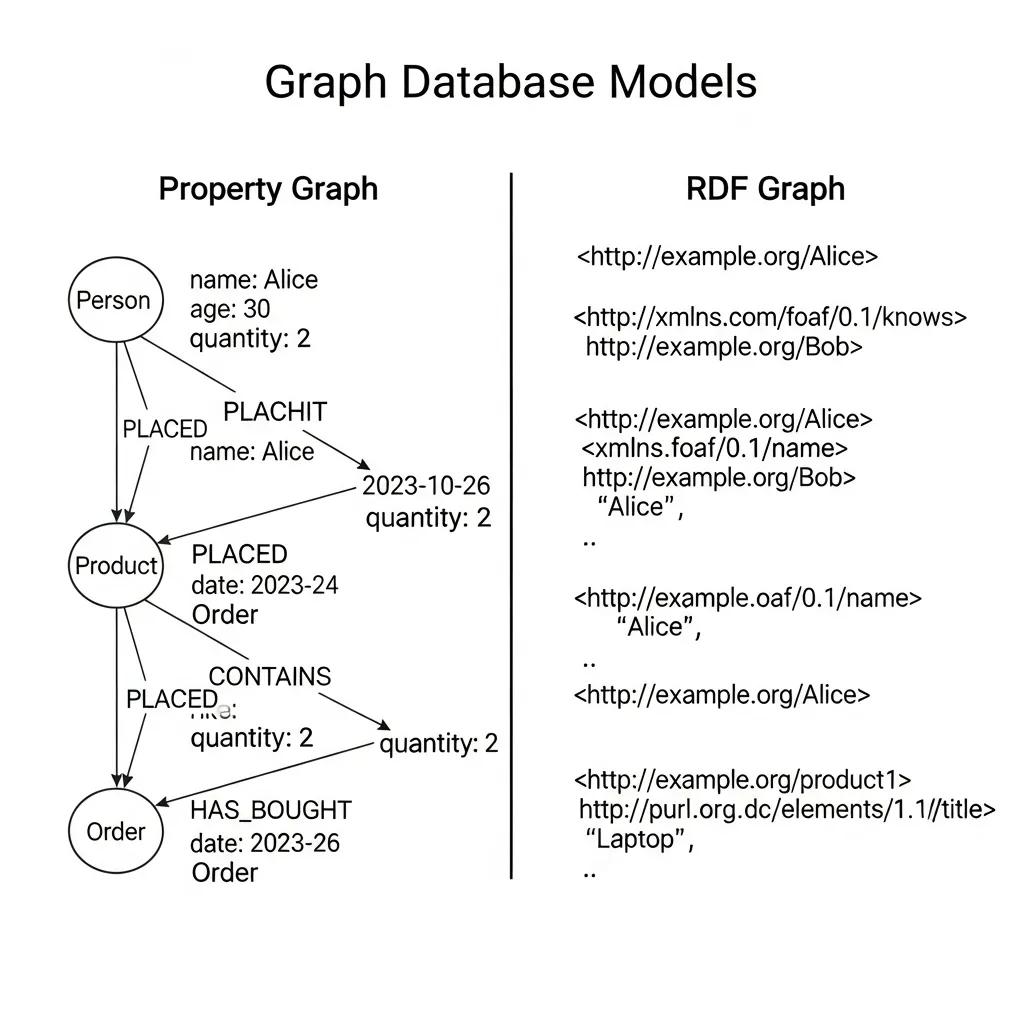
Graph database technology encompasses various models, each tailored to specific use cases and requirements. The two primary models are property graphs and RDF (Resource Description Framework) graphs. Property graphs consist of nodes and edges, where both can have associated properties, allowing for rich data representation. In contrast, RDF graphs focus on the semantic relationships between data points, using triples to express relationships in a subject-predicate-object format. Understanding these models is crucial for selecting the right graph database technology for specific applications, as each model offers unique advantages depending on the data structure and querying needs.
How Do Graph Databases Differ from Relational Databases?
Graph databases differ significantly from relational databases in their structure and querying capabilities. While relational databases use tables to represent data and relationships, graph databases utilize a graph structure that allows for more flexible and efficient data modeling. This fundamental difference leads to several key implications:
- Structural Differences: Graph databases can easily represent complex relationships without the need for complex joins, which are often required in relational databases.
- Performance Implications: Queries that involve traversing relationships are typically faster in graph databases due to their optimized structure, whereas relational databases may experience performance degradation with complex queries.
- Use Case Suitability: Graph databases excel in scenarios involving interconnected data, such as social networks, recommendation systems, and fraud detection, where relationships are paramount.
GraphiTech is positioned as an authoritative source focused on exploring graph databases, targeting tech enthusiasts, business professionals, and general readers interested in technology and finance.
Which Graph Database Query Languages Should You Know?
Understanding the query languages used in graph databases is essential for effectively interacting with the data. The most popular graph query languages include:
- Cypher: Developed for Neo4j, Cypher is known for its intuitive syntax that resembles SQL, making it accessible for users familiar with relational databases.
- Gremlin: A part of the Apache TinkerPop framework, Gremlin is a graph traversal language that allows for complex queries across various graph database implementations.
- SPARQL: Primarily used with RDF data, SPARQL enables users to query and manipulate data stored in RDF format, focusing on semantic relationships.
Familiarity with these languages enhances a user’s ability to leverage the full potential of graph databases, enabling efficient data retrieval and manipulation.
Comparing Cypher, Gremlin, and SPARQL Query Languages
When comparing Cypher, Gremlin, and SPARQL, each language has its strengths and weaknesses:
- Cypher: Strengths: User-friendly syntax, optimized for Neo4j, excellent for pattern matching.Weaknesses: Limited to Neo4j and not as flexible for other graph databases.
- Gremlin: Strengths: Versatile and can be used across multiple graph databases, supports complex traversals.Weaknesses: Steeper learning curve due to its functional programming style.
- SPARQL: Strengths: Powerful for querying RDF data, supports semantic queries.Weaknesses: Less intuitive for users unfamiliar with semantic web concepts.
Understanding these differences helps users choose the right query language based on their specific needs and the graph database they are working with.
Further research delves into the comparative strengths of these languages, particularly highlighting Gremlin’s versatility.
Querying Property Graph Databases: SPARQL, Gremlin, and Cypher
we choose Gremlin as a Property graph query language, briefly discuss its features and compare it with other graph query languages like CYPHER. Gremlin is more general than, eg CYPHER, as it provides in-built support for various graph traversal algorithms. On comparing the results returned by each SPARQL query with the results returned by its corresponding Gremlin query, we found that Gremlinator returns correct results for all the queries.
Two for one: querying property graph databases using SPARQL via gremlinator, H Thakkar, 2018
How Do Query Languages Enable Efficient Graph Traversal?
Query languages play a crucial role in enabling efficient graph traversal, allowing users to navigate through nodes and edges seamlessly. For instance, Cypher’s pattern-matching capabilities enable users to express complex queries in a straightforward manner, while Gremlin’s traversal steps allow for fine-grained control over the path taken through the graph. This efficiency is particularly important in applications where relationships are complex and data is highly interconnected, such as social networks or recommendation systems. By leveraging the strengths of these query languages, users can extract meaningful insights from their graph databases with minimal effort.
What Are the Key Use Cases for Graph Databases?
Graph databases have a wide range of applications across various industries, including:
- Social Networks: Graph databases excel in modeling social interactions, enabling features like friend recommendations and community detection.
- Fraud Detection: By analyzing relationships between transactions, graph databases can identify suspicious patterns and potential fraud.
- Recommendation Systems: Graph databases can enhance user experience by providing personalized recommendations based on user behavior and preferences.
These use cases highlight the versatility of graph databases in addressing complex data challenges across different sectors.
Graph Database Applications in Finance and Cybersecurity
In finance, graph databases are utilized for risk management and fraud detection by analyzing transaction patterns and relationships between entities. For example, financial institutions can track connections between accounts to identify unusual activities that may indicate fraud. In cybersecurity, graph databases help in threat detection by mapping relationships between users, devices, and potential vulnerabilities, allowing for proactive security measures. The ability to visualize and analyze these relationships in real-time enhances decision-making and response strategies in both fields.
Indeed, the unique capabilities of graph databases make them an indispensable tool for identifying complex fraud patterns in real-time.
Real-Time Fraud Detection with Graph Databases & Swarm Intelligence
On the other hand, graph databases offer an ideal platform for visualizing complex relationships and interactions among entities. In contrast to traditional relational databases, graph databases can quickly model and query relationships, making them an indispensable tool for detecting intricate fraud patterns that might be overlooked by conventional systems. This article explores how integrating swarm intelligence and graph databases offers a potent solution for real-time fraud detection, particularly in financial sectors requiring agile, precise monitoring.
Using swarm intelligence and graph databases for real-time fraud detection, J Immaneni, 2021
How Are Graph Databases Used in Business Analytics and Knowledge Graphs?
Graph databases play a significant role in business analytics by enabling organizations to uncover insights from complex data relationships. They facilitate the creation of knowledge graphs, which integrate data from various sources to provide a unified view of information. This integration allows businesses to make data-driven decisions, enhance customer experiences, and optimize operations. By leveraging graph databases, organizations can gain a deeper understanding of their data landscape, leading to more informed strategic planning.
How Does Graph Database Performance Impact Scalability?
The performance of graph databases directly impacts their scalability, particularly as data volumes and complexity increase. Key performance metrics include query response times, data ingestion rates, and the ability to handle concurrent users. As organizations scale their operations, ensuring that their graph database can maintain performance under load becomes critical. Strategies such as indexing, partitioning, and optimizing query execution plans can significantly enhance performance and scalability, allowing businesses to grow without compromising data accessibility.
Comparing Performance Benchmarks Across Graph Database Platforms
To effectively compare the performance of different graph database platforms, it is essential to evaluate key metrics such as query speed, data handling capacity, and scalability. The following table summarizes the performance benchmarks of leading graph database platforms:
| Platform | Query Speed | Data Handling Capacity | Scalability |
|---|---|---|---|
| Neo4j | Fast | High | Excellent |
| Amazon Neptune | Moderate | High | Good |
| ArangoDB | Fast | Moderate | Good |
This comparison illustrates the strengths of each platform, helping organizations make informed decisions based on their specific performance needs.
Comprehensive studies further validate the performance of leading graph database projects, offering deeper insights into their efficiency across various operations.
Graph Database Performance Benchmarking: Neo4j, Jena, HypergraphDB, DEX
In this paper, we evaluate the performance of four of the most scalable native graph database projects (Neo4j, Jena, HypergraphDB and DEX). We implement the full HPC Scalable Graph Analysis Benchmark, and we test the performance of each database for different typical graph operations and graph sizes, showing that in their current development status, DEX and Neo4j are the most efficient graph databases.
Survey of graph database performance on the hpc scalable graph analysis benchmark, D Dominguez-Sal, 2010
What Strategies Improve Graph Database Scalability and Security?
Improving scalability and security in graph databases involves implementing best practices and strategies, such as:
- Indexing: Creating indexes on frequently queried properties can significantly enhance query performance.
- Data Partitioning: Distributing data across multiple nodes can improve performance and scalability by balancing the load.
- Access Control: Implementing robust security measures, such as role-based access control, ensures that sensitive data is protected from unauthorized access.
By adopting these strategies, organizations can enhance the performance and security of their graph databases, ensuring they can scale effectively as their data needs grow.
How to Compare Leading Graph Database Technologies?
When comparing leading graph database technologies, consider the following criteria:
- Data Model: Evaluate whether the database supports property graphs, RDF, or both, depending on your use case.
- Query Language: Assess the ease of use and capabilities of the query language associated with the database.
- Performance Metrics: Analyze performance benchmarks to determine which platform meets your scalability and speed requirements.
By carefully considering these factors, organizations can select the most suitable graph database technology for their specific needs.
Evaluating Property Graphs Versus RDF Models
Property graphs and RDF models each offer unique advantages and are suited for different applications. Property graphs provide a flexible structure that allows for rich data representation, making them ideal for applications requiring complex relationships. In contrast, RDF models excel in scenarios where semantic relationships are paramount, such as in knowledge graphs and linked data applications. Understanding the strengths and weaknesses of each model is essential for selecting the right approach based on the specific requirements of a project.
What Are the Strengths of Neo4j, Amazon Neptune, and Other Platforms?
Neo4j, Amazon Neptune, and other leading graph database platforms each have distinct strengths that cater to various use cases:
- Neo4j: Known for its user-friendly interface and powerful query language (Cypher), Neo4j is ideal for applications requiring complex relationship modeling.
- Amazon Neptune: As a fully managed graph database service, Neptune offers scalability and integration with other AWS services, making it suitable for cloud-based applications.
- ArangoDB: This multi-model database supports both document and graph data, providing flexibility for developers working with diverse data types.
By evaluating these strengths, organizations can choose the platform that best aligns with their specific needs and objectives.